 Introduction: This encounter begins with an idea, a “bump,” from Harry Keller, which first appeared in an etcnews-l listserv post on 8 Oct. 2009. To participate in this encounter, post a comment. I’ll append most or all of the comments to this post as they’re published. -js
Introduction: This encounter begins with an idea, a “bump,” from Harry Keller, which first appeared in an etcnews-l listserv post on 8 Oct. 2009. To participate in this encounter, post a comment. I’ll append most or all of the comments to this post as they’re published. -js


Harry Keller, editor, science education, on 8 Oct. 2009, 9:26AM: Has anyone seen Google’s Sidewiki feature? It’s pretty scary if you begin to think about it as this blogger [Paul Myers, TalkBiz News: The Blog] has in “Google Steals the Web.” Can any of you calm my trepidation regarding this potentially serious problem?
 Claude Almansi, editor, accessibility issues, and ETC site accessibility facilitator, on 8 Oct. 2009, 11:28 pm: Errh, Jim and Harry, am I missing something in this very long and detailed article? In what is Sidewiki new? The same commenting feature is offered by Diigo bookmarking, and Diigo has been around since 2006.
Claude Almansi, editor, accessibility issues, and ETC site accessibility facilitator, on 8 Oct. 2009, 11:28 pm: Errh, Jim and Harry, am I missing something in this very long and detailed article? In what is Sidewiki new? The same commenting feature is offered by Diigo bookmarking, and Diigo has been around since 2006.
I used Diigo comments on Myer’s article: they all can be viewed by clicking here, even by people who don’t have a Diigo account, as I made them public, whereas only people who have installed Sidewiki on their Google bar can see the Sidewiki comments, according to that article. And people who install a browsing feature on a toolbar should be aware of what it does. I have twittered my bookmark, and I could have my Diigo bookmarks – and thus my public comments – showing on my Facebook page. And I’m not sure Diigo has the filtering-through-algorithms capacity Google Sidewiki has, however imperfect that might be.
So in what way is Google Sidewiki worse than Diigo comments? When I mentioned having added Diigo comments to the e-codices electronic version of Historia destructionis Troiae, the person in charge of the e-codices project did not get his knickers in a twist over my “stealing his content” or “hijacking his server.” He wrote that he had actually been trying to implement something like that for users to comment, just that the Diigo commenting solution was not user-friendly on pictures (true, it works better on text). Maybe he took it serenely because, being a tech person, he really understood how these commenting web apps work. Which apparently the author of the article only does partially.
These social commenting features can be fabulous for learning projects involving several schools, for instance. With Diigo, at least, you can choose to share your bookmarks or individual comments with a group, and Diigo has keyboard shortcuts that make it accessible to the blind. Teachers wishing to do the same with Sidewiki should check if there are the same shortcuts. I’m not going to install the needed toolbar as I already have the Diigo and Webdeveloper ones (not that I am a web developer, but it is very useful to get concrete evidence of why a site makes you queasy).
Harry Keller (10.9.09, 4:17AM): I have never seen Diigo before and hadn’t heard of Sidewiki before reading the article and have never used it. Given those caveats, here’s my take.
For the crowd that has Google toolbar, a huge number of people, they will be asked to add Sidewiki. The pitch will be seductive: social commenting. Sounds great. Most will do so. I’d expect millions of Sidewiki users in short order.
If I don’t have Sidewiki, then comments about my site will be invisible to me. However, any member who arrives at my site will see them all right there along with my intended site. In other words, they don’t have to go to Sidewiki.com to view the comments. They only have to go to smartscience.net, possibly as the result of a Google search. The right portion of my site will be cut off to make room for the Sidewiki, which will not be cut off at all. Those comments will be more prominent than my site. Whenever I send out http://www.smartscience.net to anyone, the possibility exists that they will see any comments. Those comments can be from anyone, including competitors.
It would be very easy for a competitor to use newly created and fake Gmail account to leave false comments about my service on the site. Then, every Sidewiki user who uses my site would see the negative comment and would probably believe it. Sidewiki users might see the comment and repeat it on various other social networks. I would have no recourse except to complain to Google, who could take their time reviewing the complaint and even decide to leave it alone. However, in a very sinister twist, I wouldn’t even know about the sabotage unless I join Sidewiki.
So, the problem has two parts. The first part is that your own URL would deliver Sidewiki, not some other Google-owned URL. The second part is the ease with which those who would do you grief can sabotage your Sidewiki “enhanced” site without your knowledge.
 John Adsit, editor, curriculum & instruction, K-12, on 9 Oct. 2009, 4:42AM: I share Harry’s concern, with a sense of real despair.
John Adsit, editor, curriculum & instruction, K-12, on 9 Oct. 2009, 4:42AM: I share Harry’s concern, with a sense of real despair.
Let’s say Google comes to its senses and decides not to do it.
So what? If it can be done, someone will do it. Perhaps the solution is to get Google and other organizations with decent reputations to shun that technology leave it to some organization so unscrupulous that anything that appears in it will have no credibility to the average viewer, who will see it as a nuisance rather than a valuable asset.
Claude Almansi (10.9.09, 5:45AM):
[Harry Keller:] I have never seen Diigo before and hadn’t heard of Sidewiki before reading the article and have never used it. Given those caveats, here’s my take.
For the crowd that has Google toolbar, a huge number of people, they will be asked to add Sidewiki. The pitch will be seductive: social commenting. Sounds great. Most will do so. I’d expect millions of Sidewiki users in short order.
If I don’t have Sidewiki, then comments about my site will be invisible to me. However, any member who arrives at my site will see them all right there along with my intended site. In other words, they don’t have to go to Sidewiki.com to view the comments. They only have to go to smartscience.net, possibly as the result of a Google search. The right portion of my site will be cut off to make room for the Sidewiki, which will not be cut off at all. Those comments will be more prominent than my site. Whenever I send out http://www.smartscience.net to anyone, the possibility exists that they will see any comments. Those comments can be from anyone, including competitors.
It would be very easy for a competitor to use newly created and fake Gmail account to leave false comments about my service on the site.
Same with Diigo.
Then, every Sidewiki user who uses my site would see the negative comment and would probably believe it.
If they are Sidewiki users themselves – and they have to be in order to view the comments – they’ll be able to tell the difference between web page and comments.
Sidewiki users might see the comment and repeat it on various other social networks.
From what I understood, you can only share your own Sidewiki comments to other social networks.
I would have no recourse except to complain to Google, who could take their time reviewing the complaint and even decide to leave it alone. However, in a very sinister twist, I wouldn’t even know about the sabotage unless I join Sidewiki.
Same with Diigo sticky notes: you don’t see them unless you are signed into your Diigo account.
So, the problem has two parts. The first part is that your own URL would deliver Sidewiki, not some other Google-owned URL. The second part is the ease with which those who would do you grief can sabotage your Sidewiki “enhanced” site without your knowledge.
Sorry if I was not clear: you can view Diigo sticky notes in the Diigo bookmarking page, AND you can also view them on the site they have been made at, just like Sidewiki comments. For example, click here (from <http://lenovosocial.com/discover/social-site-reviews/diigo/>). They are actually far more invasive than Sidewiki, which stays put in a column on the left of the commented page.
So the Diigo sticky notes present exactly the same potential risks as the Google Sidewiki comments. With the added risk that they are more invasive and can be collected by people who don’t have a Diigo account on the bookmarking page as well. I made 37 frigging Diigo sticky notes on the article you sent, btw.
In nuce: the only way to prevent folks from commenting what you write is not to publish it: whether the authors liked it or not, people wrote comments directly on medieval manuscripts, on printed books, now they do on websites too.
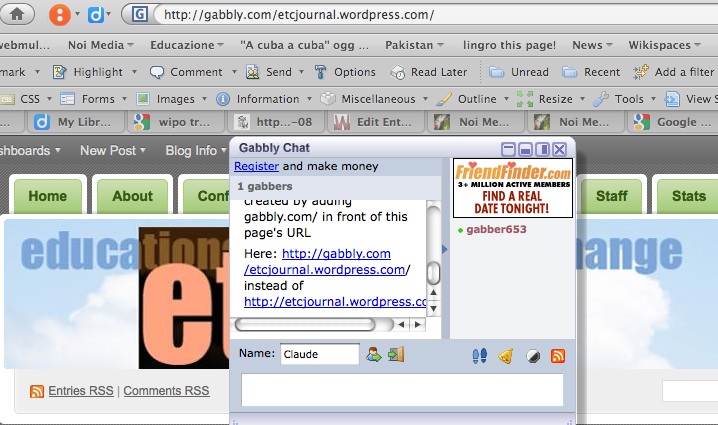
BTW, before Diigo and Sidewiki, there was – still is – Gabbly, which allows you to add a chat to any web page by adding “gabbly.com/” in front of any URL – for instance <http://gabbly.com/etcjournal.wordpress.com/>. Click here for an example.
That could be annoying, too, couldn’t it? I remember joking with a friend about creating such a gabbly chat to promote The Pirate Bay on the site of MPAA or RIAA. And I did that one without registering at gabbly. If you register, you can make money from ads as well. Gabbly has been around for years, and so far as I know there have not been any protests about it.
Claude Almansi (10.9.09, 6:16AM): John, from a search about Gabbly, I got to Gooey, which is apparently the mother of all these applications that allow you to write comments on a web page. So the tech has been around since 1999. As to your suggestion, people who have been using Diigo sticky notes for years for entirely legit research and teaching purposes would not take kindly to Diigo removing this great feature because some people just realized that it has been possible to add comments on a web site unbeknown to the site’s author for 10 years and don’t like it.
Moreover, this is the same tech that enables online captioning of videos e.g. at Overstream.net. And if you can add captions, you can also add comments. So should that captioning possibility be scrapped too?
Why don’t you and Harry trust users’ intelligence a bit more? If a user can view sidewiki, it means s/he has it on her/his toolbar and most likely uses it too, so s/he knows how it works. Therefore it is unlikely s/he’ll be so daft as to confuse the Sidewiki content with the content of the page.

Bonnie Bracey Sutton, editor, policy issues, on 9 Oct. 2009, 6:22AM: You guys must have a lot more time than I have, but also you are not in DC where I have too many meetings to go to. I will check Sidewiki out.
Harry Keller (10.9.09, 6:53AM): I see the problem as simply that your web site URL, without any added characters — in my case, http://www.smartscience.net — would be delivered with the added comment to all of those with Google toolbars who, upon urging by Google, accepted the invitation to add Sidewiki. That fact might be just dandy for people publishing research papers and those making Internet noise with their blogs (as I have). However, it invites disaster for all organizations, for-profit and non-profit, who publicize their missions, products, and services on the Internet.
Don’t like the Red Cross? Just Sidewiki-swipe it. Upset that your competitor landed that big contract that you should have? Sidewiki-swipe their site with allegations about sexual misconduct or misappropriation of funds or any other negative stuff you can imagine. Assuming that lots of people have Sidewiki, the allegation could quickly go viral and be unstoppable. Such allegations in blogs are shrugged off these days. You have to find your way to the particular blog, after all. A competitor’s blog would have to be found and would not contain really nasty claims about competition because it would reflect poorly on the company.
On the other hand, the ugly comments would appear to every Sidewiki user who happened upon your site in its native, unamended, and true location in web space: its URL.
I really do not like the idea of my own URL being directly contaminated with stuff over which I have no control. Control of your own web site is a central concept of the Internet.
Furthermore, I have devoted my technical resources for ten years to creating a Web 2.0 resource (although it wasn’t called that when I began). Every customer starts at a specific URL in order to use our service. I may be able to take down my marketing URL, smartscience.net, and avoid Sidewiki problems there. However, I cannot take down my production site. Someone could put pornographic references there for any 6th grade student using my service, and it would reflect on me personally. My business would disappear in a heart beat. A decade of outrageously hard work and self-denial would be snuffed out before I even knew what was happening.
As I said before, I don’t know about Diigo or the others, but I suspect that they have not tied into the unvarnished URLs of web sites as has Google so that when your browser hits that site, whether you care or not, the Sidewiki panel appears. You should have to use another URL or specifically ask for comments. My web site is my web site and my URL should display it and it alone.
 David Lebow, on 9 Oct. 2009, 8:48AM: I remember people speculating about third-party annotation in the early ‘90s with the advent of the Mosaic browser. Even then, people were concerned about “trespassing” as a problem.
David Lebow, on 9 Oct. 2009, 8:48AM: I remember people speculating about third-party annotation in the early ‘90s with the advent of the Mosaic browser. Even then, people were concerned about “trespassing” as a problem.
The alternative solution to Sidewiki is to provide “owners” of websites and web pages with Java script libraries and APIs that add third-party annotation. Owners could then choose to add social annotation to their web pages while maintaining control over postings.
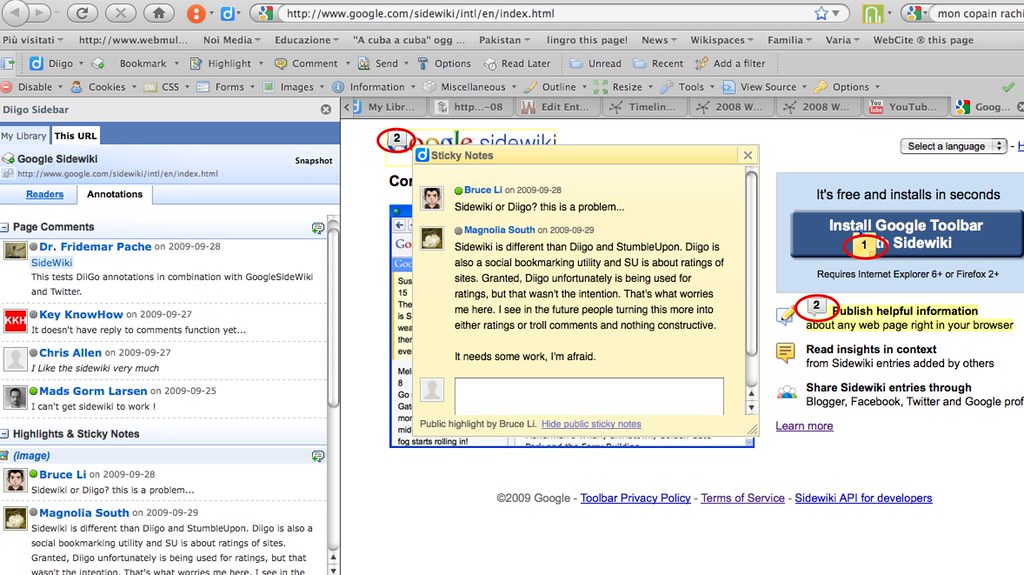
Claude Almansi (10.9.09, 9:51AM): Hi Harry. Diigo also works on the web site URL, without any added characters. Click here for an example of a screenshot of the Google page for Sidewiki when viewed by Diigo.com subscribers with the Diigo side navigation bar activated and one set of sticky notes opened inside the web site. I have circled in red the points were Diigo.com subscribers have added sticky notes. I did the screenshot opening the sticky notes set with the one by “Magnolia South” for you, because it is the most critical about Sidewiki.
It is true that Diigo is partly safeguarded from people who would use its sticky notes for trolling because its primary purpose is social bookmarking, and trolls are not much into that. But if the Google anti-troll filter proves efficient enough, trolls will well fall back on Diigo.
[Harry Keller:] Don’t like the Red Cross? Just Sidewiki-swipe it. Upset that your competitor landed that big contract that you should have? Sidewiki-swipe their site with allegations about sexual misconduct or misappropriation of funds or any other negative stuff you can imagine. Assuming that lots of people have Sidewiki, the allegation could quickly go viral and be unstoppable. Such allegations in blogs are shrugged off these days. You have to find your way to the particular blog, after all. A competitor’s blog would have to be found and would not contain really nasty claims about competition because it would reflect poorly on the company.
On the other hand, the ugly comments would appear to every Sidewiki user who happened upon your site in its native, unamended, and true location in web space: its URL.
Sidewiki users would immediately know that the comments were done by another Sidewiki user, and would take them with the same skepticism as they would if they stumbled upon an external blog entry. (…)
As I said before, I don’t know about Diigo or the others, but I suspect that they have not tied into the unvarnished URLs of web sites as has Google so that when your browser hits that site, whether you care or not, the Sidewiki panel appears. You should have to use another URL or specifically ask for comments. My web site is my web site and my URL should display it and it alone.
Granted, Gabbly does not tie into the “unvarnished URLs of websites,” as you have to add gabbly.com after http:// to create the Gabbly chat. But – see above – Diigo does, and has done so for 3 years now, whether you like it or not. So far no Diigo user has added sticky notes to your web site, but it might happen, just as with Sidewiki. If it does, don’t take it too hard. If the comments are legit and constructive, let them be. If they are not, ask the administrators of whichever platform is involved to remove them.
Again, please trust people’s intelligence a bit more: even if the comments appear on the left of your website at its unvarnished URL, they are quite clearly external comments that have nothing to do with the site – both with Diigo and Sidewiki.
PS re your Red Cross example: I confess I have been sorely tempted to add a sticky note to their job application page opened with Firefox, which tells you you have to use Internet Explorer. Quoting the staff officer who told me to go to a cybercafe to use IE there if I don’t have it, as there is no single other way to apply for a Red Cross job. I didn’t, because folks using IE would not see that message for non-IE-users, and because, well, I want to use Diigo for constructive things.
Harry Keller (10.9.09, 12:20PM): Hi Claude, I just have to assume, without any other information, that Diigo is potentially evil too. Given that this all is true, then the major difference is that Google is ubiquitous and so, much more dangerous. My issue is with people searching for “virtual labs” and clicking on the link to smartscience.net, seeing the stuff on the side, and assuming that it’s all true or that I’m somehow responsible.
Among means to thwart this problem are some clever java_script code (defeated if user has java_script off) and simply swarming your pages with your own positive comments and so drowning out any others.
Although the potential for this problem occurred with the first search engine, two big things had to happen since the advent of the Internet. First, commercial sites had to be possible. In the early days they would be flamed. Purists believed that the Internet should not contain commercial messages.
The second was the virtual monopoly of one search engine. I used to think it would be Alta Vista. Was I ever wrong. When a company name becomes a verb, you know trouble is just around the corner.
Although tagging of web sites sounds great in theory, it’s really a dangerous way to run things.
Filed under: Uncategorized | Tagged: Diigo, Google, Sidewiki | Leave a comment »


 By Claude Almansi
By Claude Almansi































































































































































































































































































































































































































































































































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}